UniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
Keywords: Robot Reinforcement Learning, Systems, Heterogeneous Training

#Abstract
Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop.
We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, FastSAC, FlashSAC, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by $3\text{--}10\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends.
These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://unilabsim.github.io.
#1. Introduction
Training infrastructure has become a first-order factor in simulation-based robot RL: faster training reduces the wall-clock cost of a single experiment, shortens system and algorithm iteration cycles, and expands the range of tasks that can be studied under practical hardware budgets. The dominant answer in recent years has been clear: place physics simulation, rollout collection, and learning on a GPU-centric execution path; Isaac Gym, Isaac Lab, MuJoCo Playground, mjlab, ManiSkill3, and Genesis show that large-scale GPU-resident environment parallelism can greatly accelerate robot control training. This success has shaped the current community default that efficient training should be organized around GPU-resident physics, tying high-throughput experimentation to a narrower set of GPU-resident software environments.
Robot RL training, however, is a closed-loop system coupling data generation, policy updates, and synchronization constraints, not a simulator benchmark alone. In simulation-dominated tasks, end-to-end efficiency depends on simulation throughput, learner utilization, collector–learner synchronization, data movement and buffering overhead, and whether hardware is allocated to the stage that actually limits wall-clock time: the learner may wait for rollouts, collectors may wait for new parameters, and data movement or buffering may erase parallel gains. Whether physics runs on the GPU is therefore one design choice within a broader systems organization problem.
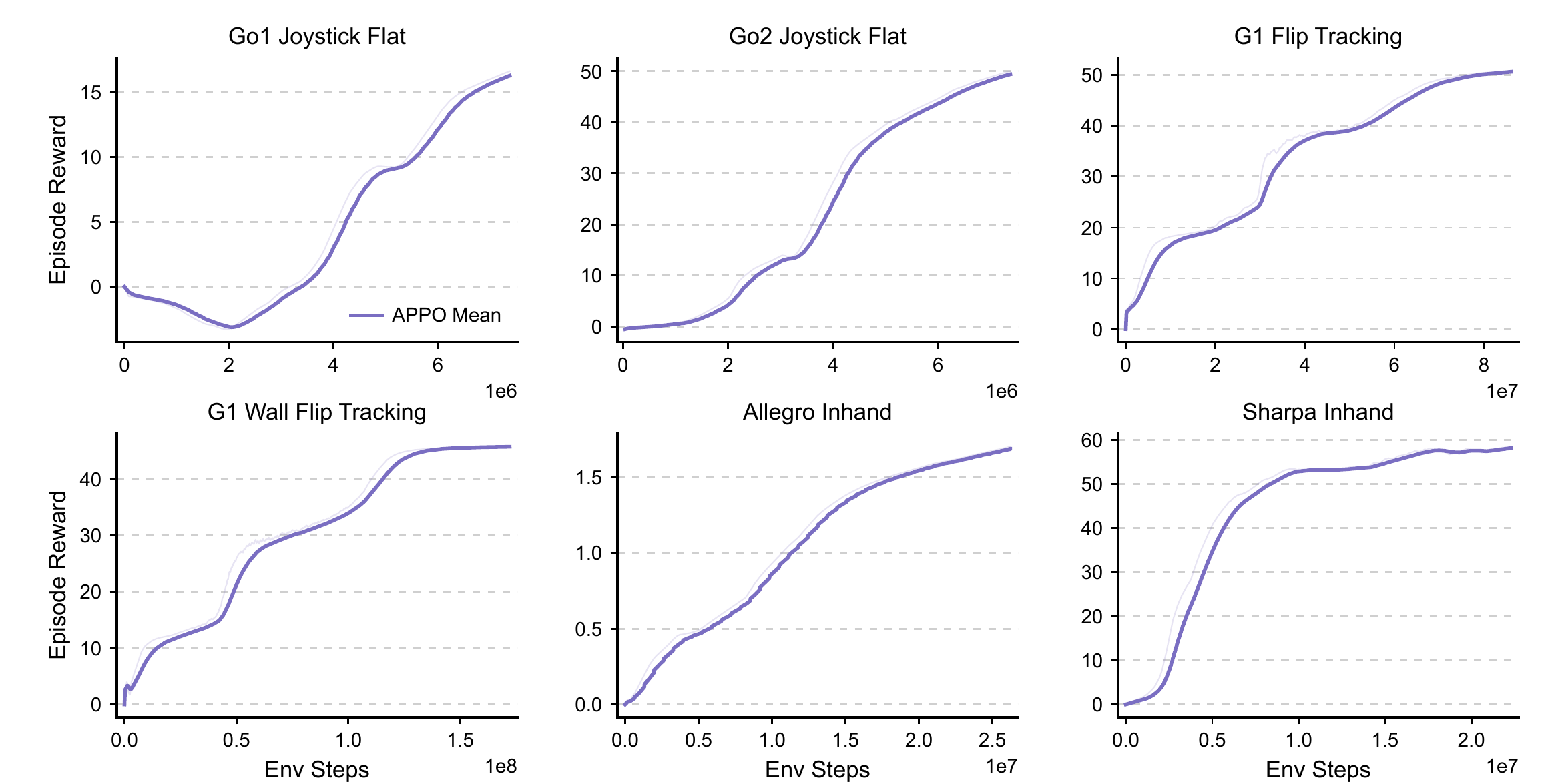
High-throughput environment execution is also possible outside GPU-resident physics. General RL systems have long used CPU-side vectorized or batched environments, and robot RL has precedents for CPU-distributed or CPU-parallel simulation, including OpenAI's Rubik's-cube hand system and recent RaiSim-based locomotion work. Algorithmic data dependencies further shape this organization: PPO preserves the strongest rollout/update synchronization constraint; APPO allows collection and learning to overlap while remaining close to the on-policy setting; and off-policy methods such as FastSAC and FlashSAC further relax the dependence of each update on trajectories from the latest policy. This ordering lets us study algorithms as synchronization regimes: PPO tests whether CPU simulation can sustain strictly synchronized training, APPO tests collector–learner overlap once synchronization is relaxed, and FastSAC/FlashSAC test the replay-based producer–consumer path. This motivates the systems question studied here: can CPU-side batched rigid-body simulation, GPU-side policy learning, and the runtime path between them form an efficient end-to-end training loop?
This paper asks whether efficient simulation-based robot control training must rely on GPU-resident simulation. Our thesis is that simulation-dominated robot control training requires high-throughput, well-coordinated simulation-learning execution, rather than GPU-resident simulation itself. We focus on representative robot control tasks in simulation, leaving real-world RL and vision-dominated settings outside the scope of this paper.
We present UniLab, a heterogeneous CPU-simulation / GPU-learning training architecture. CPU-side MuJoCoUni and MotrixSim backends perform batched rigid-body simulation and data generation, GPU resources perform policy and value learning, and a unified runtime coordinates data movement, buffering, and synchronization. UniLab is a training-system organization rather than a new policy optimization algorithm; it is implemented as a complete and extensible training system with unified training and evaluation entrypoints and explicit task/backend interfaces, while supporting PPO, FastSAC, FlashSAC, and APPO in one framework.
Across representative simulated robot-control benchmarks, UniLab improves end-to-end training efficiency by $3\text{--}10\times$ on the same single-GPU/single-CPU workstation, while reducing dependence on the NVIDIA CUDA-based software stack and supporting execution on Apple macOS, AMD ROCm, and Intel XPU backends. Our contributions are threefold:
- Systems framing. We recast efficient robot RL training as a systems organization problem for the simulation-learning closed loop, rather than a consequence of GPU-resident physics alone.
- Heterogeneous training architecture. We present UniLab, which connects CPU-batched physics backends, a GPU learner, data buffering, and parameter synchronization through a unified runtime, while supporting PPO, FastSAC, FlashSAC, and APPO in one framework.
- End-to-end evidence. We show $3\text{--}10\times$ wall-clock gains across robot embodiments, control workloads, and practical algorithms, together with execution evidence on macOS, ROCm, and XPU backends.
#2. Related Work
#2.1 GPU-Resident Robot Learning
| System | Physics | Batch | Coupling |
|---|---|---|---|
IsaacGym | PhysX | GPU-C | GPU-sync |
IsaacLab | PhysX | GPU-C | GPU-sync |
Genesis | Taichi | GPU-C/M/R | GPU-sync |
MJP | MJX | GPU-C | GPU-sync |
MjLab | MJWarp | GPU-C | GPU-sync |
| UniLab | MJU/Mtx | CPU | H-async/sync |
Note. GPU-C/M/R: GPU batched physics on CUDA/Metal/ROCm. GPU-sync: synchronized GPU simulation–learning; H-async/sync: CPU simulation with GPU learning. MJU/Mtx/MJP: MuJoCoUni/MotrixSim/MuJoCo_playground.
The dominant systems path for efficient robot RL training has been to place physics simulation, rollout collection, and learning on a GPU-centric execution path. MuJoCo provides a widely used foundation for robot control simulation, while Isaac Gym, Isaac Lab, MuJoCo Playground, mjlab, ManiSkill3, and Genesis have made large-scale GPU-resident environment parallelism a standard practice for robot learning.
#2.2 Systems Lesson from GPU Simulation
The central lesson from GPU-resident systems is the integration of fast physics execution with tightly coupled rollout collection and learner updates. For on-policy methods such as PPO, this organization fits synchronized batched rollout/update cycles and has proven effective across robot-control workloads. We adopt this systems lesson but separate the training-system principle from one hardware path: efficient training requires low-overhead data generation, learning, and synchronization, while GPU kernels are most effective for regular, dense, and statically shaped execution; dynamic active contact sets, sparse interactions, collision handling, contact solving, closed-chain or other constraint handling, and contact-rich manipulation all stress this execution model.
#2.3 CPU-Parallel Environment Execution
High-throughput environment execution also has a history outside GPU-resident physics. In general RL, EnvPool, RLlib, Tianshou, and PufferLib use CPU-side vectorized, batched, or parallel rollout collection as core system components. Robot RL also has CPU-distributed or CPU-parallel precedents, including OpenAI's Rubik's-cube hand system and recent RaiSim-based locomotion work. These examples show that CPU-side environment parallelism is viable; UniLab asks whether, under the same hardware setting, modern CPU-batched simulation and a GPU learner can form an efficient end-to-end training path through a low-overhead runtime rather than only at extreme worker-cluster scale.
#2.4 Replay-Based Robot-Control Acceleration
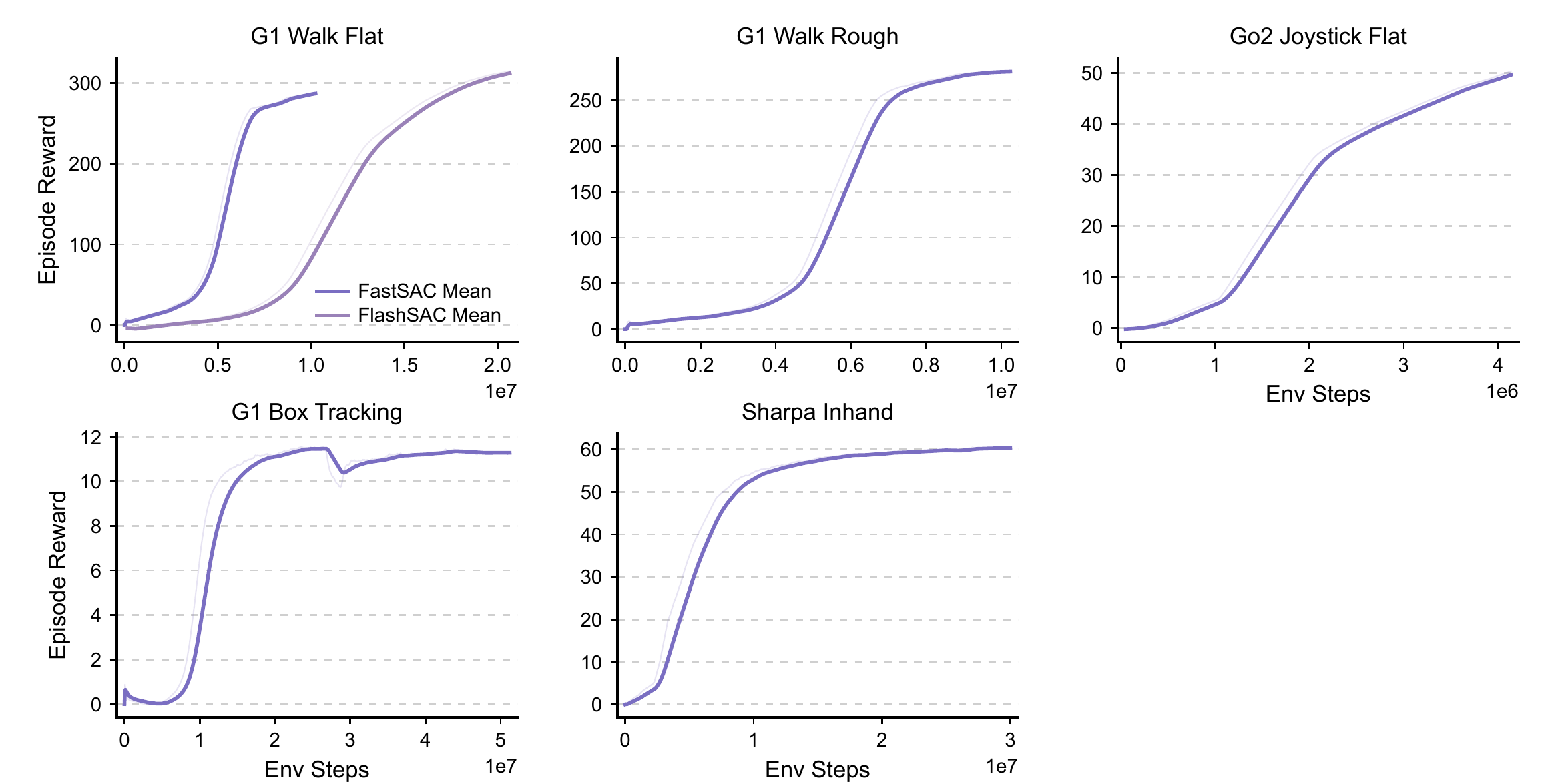
Algorithmic data dependencies further shape the system organization. PPO is the practical default in many large-scale robot-training workloads, but its on-policy updates preserve strong synchronization between rollout generation and learner updates. Replay-based methods such as SAC and TD3 can reuse past experience and relax this dependence, while FastTD3, FastSAC, and FlashSAC show that this direction can accelerate high-dimensional robot control. UniLab studies the complementary systems question: when data dependencies are relaxed, how can CPU simulation and GPU learning be coordinated to improve end-to-end wall-clock efficiency?
#3. UniLab Architecture
This section describes UniLab as an end-to-end training loop that combines CPU-side batched rigid-body simulation, GPU-side policy and value learning, and a unified runtime for coordinating the data path between them.
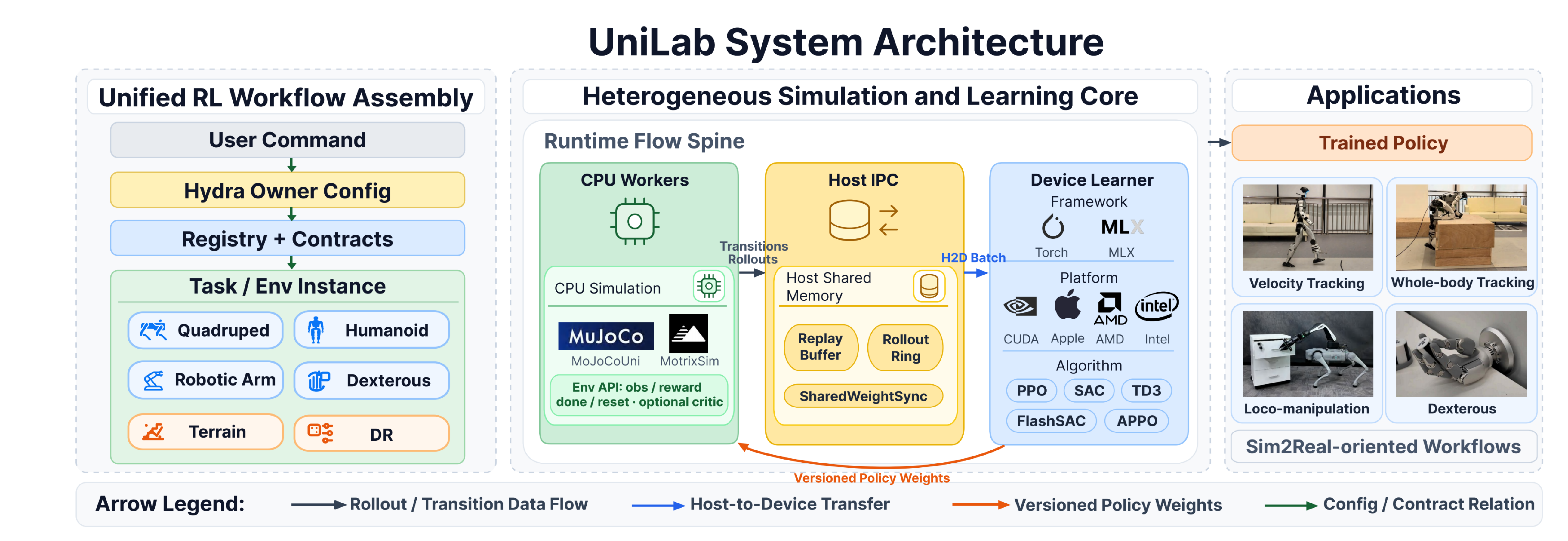
#3.1 Design Objective and Requirements
The design objective is to improve the efficiency of the full simulation-learning loop without requiring GPU-resident simulation. UniLab follows hardware roles: CPUs generate large-scale simulation data, GPUs perform dense learning updates, and the runtime minimizes coordination cost. This objective induces three requirements:
CPU-side simulation throughput. CPU-side batched rigid-body simulation must sustain enough throughput to continuously generate data for the workloads studied here.
Non-blocking GPU learning. The GPU learner should consume buffered experience rather than idling behind rollout generation.
Controlled runtime overhead. Data movement, buffering, and parameter synchronization must remain low-overhead so that the heterogeneous split does not degenerate into blocking handoffs.
#3.2 Execution Architecture
The system organization consists of: CPU workers that generate trajectories or transitions, a GPU learner that performs policy and value updates, and a unified runtime that coordinates data movement, buffering, scheduling, and parameter synchronization.
Collection–update timing and overlap. UniLab supports both synchronized and loosely coupled collection–update timing. Standard PPO uses a synchronized rollout/update cycle. APPO follows an asynchronous on-policy formulation: the collector writes fixed-horizon rollouts into a shared ring buffer while continuing on the CPU; the learner drains available rollouts and performs V-trace correction and PPO-style updates on the GPU. CPU collection and GPU learning therefore overlap in wall-clock time. FastSAC and FlashSAC use replay-based timing: collectors insert transition batches into a shared replay buffer, while the learner performs multiple updates from device batches.

Runtime abstraction. The unified runtime lets synchronized and loosely coupled execution share one system stack, connecting robot assets, task configurations, simulation backends, and learning algorithms through explicit interfaces.
#3.3 CPU Physics Backends and Task Interface
Batched CPU physics. UniLab realizes CPU-side throughput through backend-native batched environment execution: CPU workers advance environments at batch granularity and generate trajectories or transitions for the downstream learner.
Backend contract. The current system connects two practical CPU-side simulation backends under a shared runtime contract. MuJoCoUni provides a CPU-batched MuJoCo runtime backend; the MotrixSim backend maps the same task and runtime contract onto the MotrixSim physics and rendering stack.
Task and randomization interface. This contract covers task state, actions, observation-related data, reset and interval randomization hooks, terrain context, and playback capabilities. This design separates physics semantics from training throughput; the same learner binding can also target macOS, ROCm, and XPU.
#4. Experiments
We evaluate three questions: whether CPU simulation provides enough throughput, whether heterogeneous CPU-simulation / GPU-learning improves end-to-end wall-clock efficiency, and whether the result is robust across task families and algorithms.
#4.1 Experimental Setup
Controlled comparisons use the same default Linux hardware: one NVIDIA RTX 4090 GPU, one AMD Ryzen 9 9950X3D CPU, and 64 GB of 4800 MT/s memory. The task set spans locomotion, motion tracking, manipulation, and manipulation-locomotion across quadruped, wheeled-quadruped, humanoid, and dexterous-hand embodiments. Algorithms are organized by synchronization constraints: PPO (strictly synchronized), APPO (near-on-policy with overlap), and FastSAC/FlashSAC (replay-based producer–consumer).
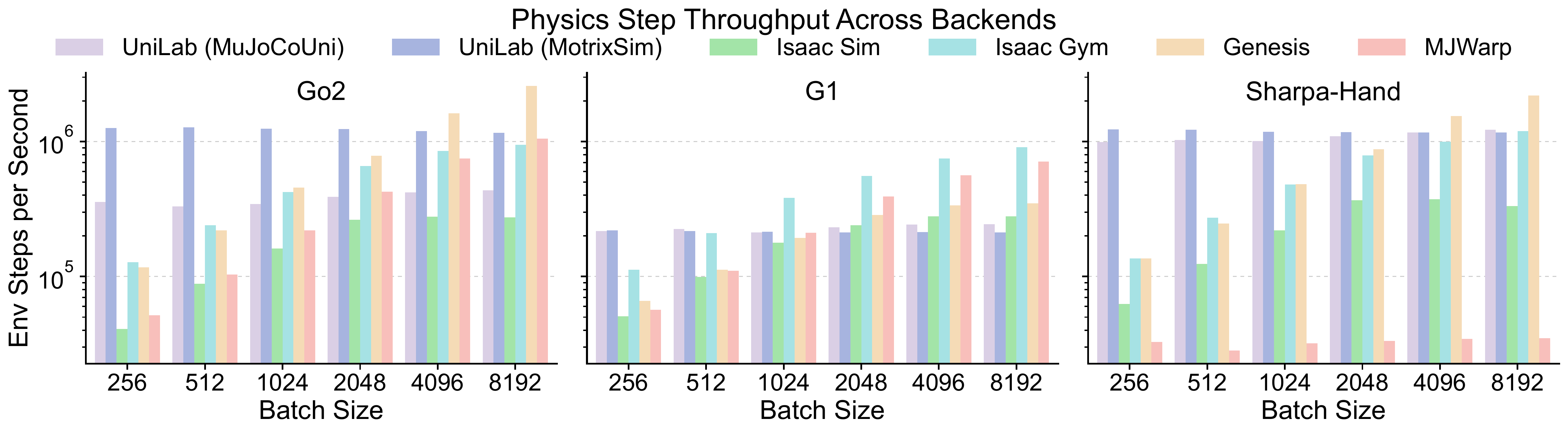
#4.2 Can CPU Simulation Provide Enough Throughput?
In common robot-RL training settings, CPU physics does not necessarily provide lower throughput than GPU-based simulation; its relative advantage is more pronounced in workloads with complex contact and dexterous manipulation. Batched CPU simulation provides the simulator-side capacity required by the heterogeneous execution model.
| Chip | Go2 | G1 | Hand | |||
|---|---|---|---|---|---|---|
| MJ | Motrix | MJ | Motrix | MJ | Motrix | |
| A18 Pro | 55.7 | 122.9 | 28.4 | 18.1 | 183.9 | 134.1 |
| M5 Max | 288.0 | 797.8 | 178.8 | 127.7 | 1118.4 | 982.9 |
| R9-8945HX | 246.2 | 704.2 | 154.6 | 113.6 | 434.1 | 542.2 |
| TR-9980X | 915.9 | 2662.7 | 517.9 | 410.4 | 1991.5 | 2622.6 |
| i7-11800H | 82.1 | 162.0 | 34.7 | 23.8 | 176.8 | 151.6 |
| Xeon 8558 | 1002.4 | 847.2 | 424.6 | 379.5 | 2566.3 | 397.7 |
Note. Values are $10^3$ env steps/s; MJ = MuJoCoUni backend.
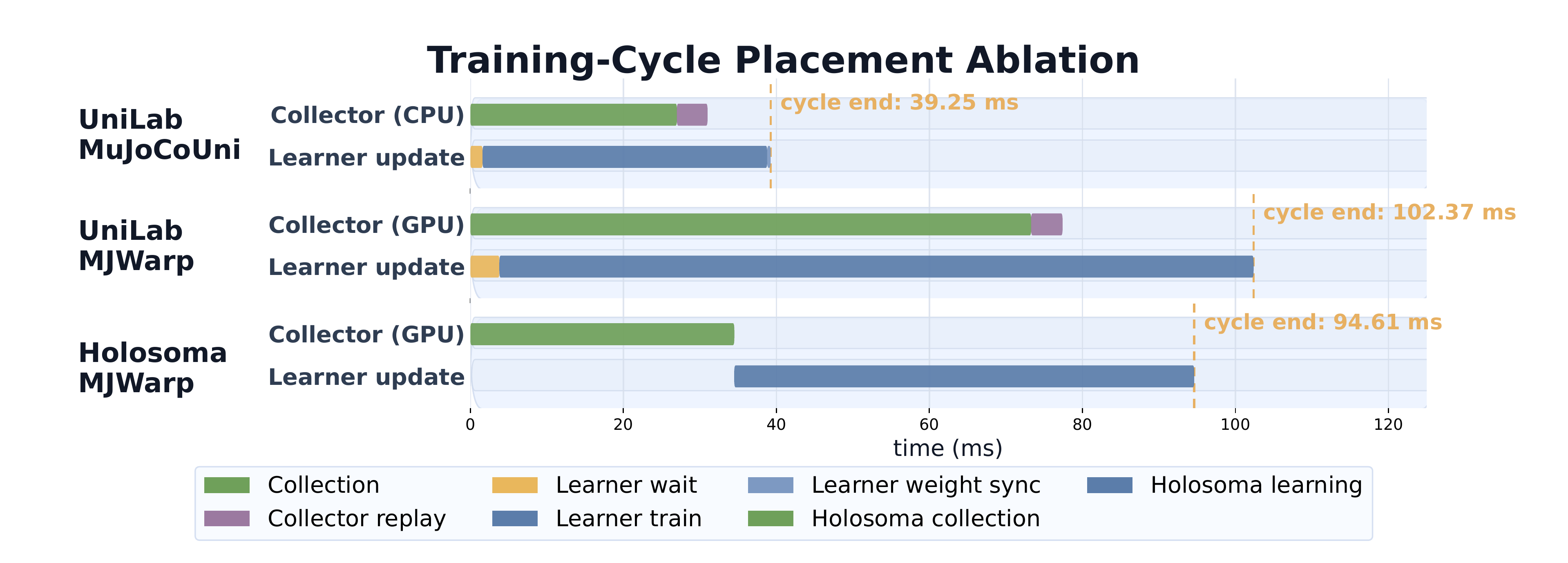
#4.3 Can CPU-Sim / GPU-Learn Improve End-to-End Efficiency?
Given sufficient CPU-side throughput for strictly synchronized PPO, the next question is whether heterogeneous organization translates into end-to-end gains as data dependencies become looser. Once the runtime decouples the learner from the collector, these more loosely coupled settings obtain $3\text{--}10\times$ improvements in end-to-end training efficiency across multiple robot control tasks.


#4.4 Dexterous In-Hand Rotation as a Systems Stress Test
SharpaWaveHand in-hand rotation adds contact-rich evidence beyond locomotion and motion tracking. In this task, the CPU MuJoCo version trains better, and UniLab reaches stronger HORA teacher policies within a shorter wall-clock budget. The task uses a 22-DOF tactile hand to rotate a randomized free object and shows that UniLab supports dense simulation, stable learning, and different synchronization constraints in dexterous teacher training.
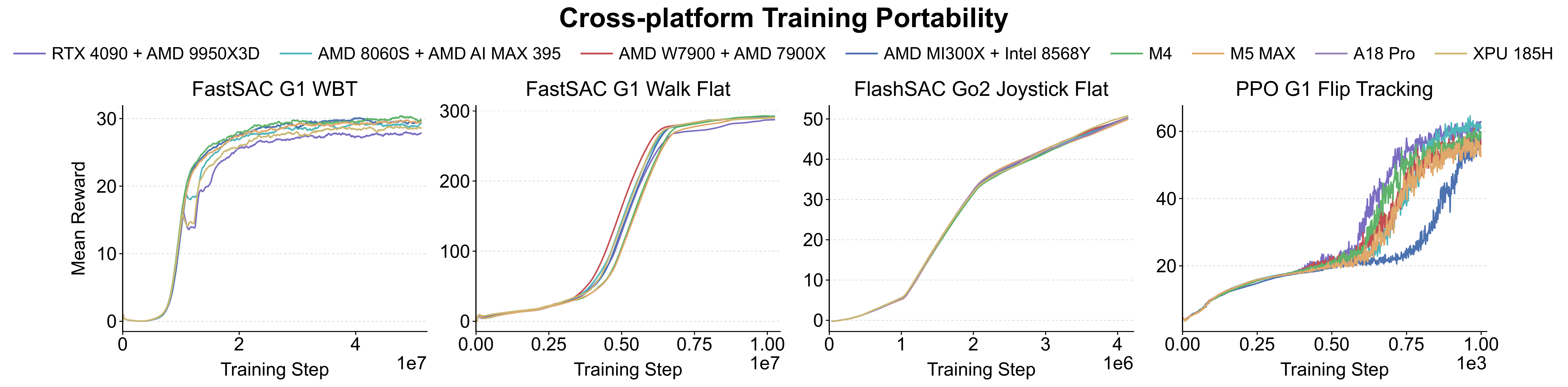
#4.5 Cross-Platform Evidence
Finally, we report Apple macOS, AMD ROCm, and Intel XPU results to show practical trainability outside a single CUDA-centric setup, without claiming absolute throughput parity with the main Linux/CUDA workstation. Cross-platform execution is a practical consequence of the UniLab interface design.
| Device | FastSAC / G1 WBT | FastSAC / G1 Walk | FlashSAC / Go2 Joy. | PPO / G1 Flip |
|---|---|---|---|---|
| RTX 4090 (Baseline) | 58.8 | 18.3 | 6.0 | 109.0 |
| RTX 4090 + AMD 9950X3D | 18.5 | 3.0 | 1.1 | 16.4 |
| AMD 8060S + AMD AI MAX 395 | 33.6 | 9.4 | 4.2 | 19.6 |
| M5 Max | 75.0 | 18.8 | 4.5 | 16.8 |
#5. Conclusion
This paper presented UniLab, a heterogeneous CPU-simulation / GPU-learning architecture for robot RL. By coordinating data movement, buffering, and synchronization through a unified runtime, UniLab improves end-to-end training efficiency by $3\text{--}10\times$ across multiple robot embodiments, control workloads, and practical algorithms, while reducing dependence on the NVIDIA CUDA-based software stack and supporting Apple macOS, AMD ROCm, and Intel XPU backends. These results show that efficient training depends on high-throughput, well-coordinated simulation-learning execution, rather than requiring physics to reside on the GPU; UniLab therefore provides a systems counterexample showing that the design space for efficient training is broader than the current GPU-centric default suggests.
#6. Discussion
Our claim is not that GPU-resident simulation is obsolete. GPU simulation may remain preferable when simulator throughput is no longer the bottleneck or when larger accelerator-rich configurations are a better fit. UniLab broadens the design space for simulation-dominated robot control.
The speed of a GPU-centric stack comes from two coupled designs: simulation, rollout collection, and learning share a low-overhead execution path, while the physics backend is organized as GPU-friendly parallel computation. The former is a training-system organization principle; the latter is one hardware path for realizing it. This path is effective for regular, dense, and statically shaped computation, but dynamic contacts, sparse interactions, collision handling, and constraint solving can increase backend engineering pressure. Thus, this paper does not challenge the value of GPU simulators; it challenges the necessity claim that efficient robot RL training must use GPU-resident physics.
#7. Limitations
The main limitations follow from three assumptions. First, UniLab is most advantageous when training is simulation-dominated and simulation can be meaningfully decoupled from learning; on strictly synchronized pipelines or vision-based workloads, CPU/GPU decoupling may yield smaller gains. Second, our claim concerns end-to-end training efficiency in a controlled single-CPU/single-GPU setting, not absolute peak throughput at extreme scale. Third, the current implementation focuses on rigid-body robot control rather than deformable objects, soft bodies, or fluids. Future work should extend the same runtime analysis to vision-dominated tasks, larger systems, and non-rigid physics.
#Acknowledgments
We thank Apple and AMD for providing hardware platforms for development and evaluation, and for assisting with platform adaptation. We are also sincerely grateful to the mjlab team for open-sourcing their excellent work, whose engineering practices provided valuable reference for this project. We also thank early users of UniLab and the students in Tsinghua University's Spring 2026 Deep Reinforcement Learning course for their use and feedback.
#References
Click to expand references (34 entries)
- V. Makoviychuk, L. Wawrzyniak, Y. Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac Gym: High performance GPU-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470, 2021.
- M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Muñoz, X. Yao, R. Zurbrügg, N. Rudin, et al. Isaac Lab: A GPU-accelerated simulation framework for multi-modal robot learning. arXiv preprint arXiv:2511.04831, 2025.
- K. Zakka, B. Tabanpour, Q. Liao, M. Haiderbhai, S. Holt, J. Y. Luo, A. Allshire, E. Frey, K. Sreenath, L. A. Kahrs, et al. MuJoCo Playground. arXiv preprint arXiv:2502.08844, 2025.
- S. Tao, F. Xiang, A. Shukla, Y. Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y. Liu, T. Chan, et al. ManiSkill3: GPU parallelized robotics simulation and rendering for generalizable embodied AI. Robotics: Science and Systems, 2025.
- Genesis Authors. Genesis: A generative and universal physics engine for robotics and beyond, December 2024.
- J. Weng, M. Lin, S. Huang, B. Liu, D. Makoviichuk, V. Makoviychuk, Z. Liu, Y. Song, T. Luo, Y. Jiang, et al. EnvPool: A highly parallel reinforcement learning environment execution engine. NeurIPS, 35:22409–22421, 2022.
- Z. Wu, E. Liang, M. Luo, S. Mika, J. E. Gonzalez, and I. Stoica. RLlib Flow: Distributed reinforcement learning is a dataflow problem. NeurIPS, 2021.
- J. Weng, H. Chen, D. Yan, K. You, A. Duburcq, M. Zhang, Y. Su, H. Su, and J. Zhu. Tianshou: A highly modularized deep reinforcement learning library. JMLR, 23(267):1–6, 2022.
- J. Suarez. PufferLib 2.0: Reinforcement learning at 1M steps/s. Reinforcement Learning Journal, 6:1378–1388, 2025.
- I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, et al. Solving Rubik's cube with a robot hand. arXiv preprint arXiv:1910.07113, 2019.
- Y. Kim, H. Oh, J. Lee, J. Choi, G. Ji, M. Jung, D. Youm, and J. Hwangbo. Not only rewards but also constraints: Applications on legged robot locomotion. IEEE Transactions on Robotics, 40:2984–3003, 2024.
- O. Pearce. Exploring utilization options of heterogeneous architectures for multi-physics simulations. Parallel Computing, 87:35–45, 2019.
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. ICML, pages 1861–1870, 2018.
- Y. Jia and J. Wu. MuJoCoUni: Persistent batched runtime primitives for MuJoCo. arXiv preprint arXiv:2605.24922, 2026.
- Motphys Team. MotrixSim: A physics simulation engine for robotics and embodied AI, 2026.
- C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, and O. Bachem. Brax – a differentiable physics engine for large scale rigid body simulation. arXiv preprint arXiv:2106.13281, 2021.
- J. Liang, V. Makoviychuk, A. Handa, N. Chentanez, M. Macklin, and D. Fox. GPU-accelerated robotic simulation for distributed reinforcement learning. CoRL, pages 270–282, 2018.
- E. Todorov, T. Erez, and Y. Tassa. MuJoCo: A physics engine for model-based control. IROS, pages 5026–5033, 2012.
- J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V. Tsounis, V. Koltun, and M. Hutter. Learning agile and dynamic motor skills for legged robots. Science Robotics, 4(26):eaau5872, 2019.
- G. B. Margolis and P. Agrawal. Walk these ways: Tuning robot control for generalization with multiplicity of behavior. CoRL, pages 22–31, 2023.
- G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal. Rapid locomotion via reinforcement learning. IJRR, 43(4):572–587, 2024.
- Z. Wang, Y. Jia, L. Shi, H. Wang, H. Zhao, X. Li, J. Zhou, J. Ma, and G. Zhou. Arm-constrained curriculum learning for loco-manipulation of a wheel-legged robot. IROS, pages 10770–10776, 2024.
- T. He, J. Gao, W. Xiao, Y. Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Pan, et al. ASAP: Aligning simulation and real-world physics for learning agile humanoid whole-body skills. arXiv preprint arXiv:2502.01143, 2025.
- Z. Cao, L. Yan, Y. Zhang, S. Chen, J. Ma, T. Zhan, S. Fu, Y. Jia, C. Lu, and Y. Gao. HiWET: Hierarchical world-frame end-effector tracking for long-horizon humanoid loco-manipulation. arXiv preprint arXiv:2602.06341, 2026.
- S. Bharthulwar, S. Tao, and H. Su. Staggered environment resets improve massively parallel on-policy reinforcement learning. NeurIPS, 38:133342–133375, 2026.
- A. A. Shahid, Y. Narang, V. Petrone, E. Ferrentino, A. Handa, D. Fox, M. Pavone, and L. Roveda. Scaling population-based reinforcement learning with GPU accelerated simulation. arXiv preprint, 2024.
- S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. ICML, pages 1587–1596, 2018.
- Y. Seo, C. Sferrazza, H. Geng, M. Nauman, Z.-H. Yin, and P. Abbeel. FastTD3: Simple, fast, and capable reinforcement learning for humanoid control. arXiv preprint arXiv:2505.22642, 2025.
- Y. Seo, C. Sferrazza, J. Chen, G. Shi, R. Duan, and P. Abbeel. Learning sim-to-real humanoid locomotion in 15 minutes. arXiv preprint arXiv:2512.01996, 2025.
- D. Kim, Y. Lee, M. Park, K. Kim, I. Nahendra, T. Seno, S. Min, D. Palenicek, F. Vogt, D. Kragic, et al. FlashSAC: Fast and stable off-policy reinforcement learning for high-dimensional robot control. arXiv preprint arXiv:2604.04539, 2026.
- M. Luo, J. Yao, R. Liaw, E. Liang, and I. Stoica. IMPACT: Importance weighted asynchronous architectures with clipped target networks. arXiv preprint arXiv:1912.00167, 2019.
- Google DeepMind. MuJoCo Warp (MJWarp), 2026.
- K. Zakka, Q. Liao, B. Yi, L. Le Lay, K. Sreenath, and P. Abbeel. mjlab: A Lightweight Framework for GPU-Accelerated Robot Learning. arXiv preprint arXiv:2601.22074, 2026.
#Appendix A. Off-Policy Replay Path Case Study
This section complements the system-attribution analysis with a detailed case study of the SAC replay-based execution path. Unless otherwise stated, all timeline statistics are computed from Perfetto traces collected on an A100 machine: one NVIDIA A100 80 GB PCIe GPU with driver 560.35.05 and CUDA 12.6, two Intel Xeon Gold 5320 CPUs with 104 logical CPU threads, and 188 GiB system memory.
#A.1 Baseline GPU-Cache SAC Path
We use SAC-A to denote the straightforward SAC baseline. It corresponds to the GPU-cache replay path before the sample-before-transfer pipeline. This baseline is already a heterogeneous design: a CPU collector process runs a CPU actor synchronized from learner weights, advances the batched environment, and writes transitions into shared CPU replay storage. The learner holds SAC actor and critic networks on the accelerator and periodically publishes updated actor weights back to the collector.
The remaining cost lies in the replay boundary. In the CUDA path, the learner maintains a device-side replay cache. When the learner samples, newly appended replay rows are lazily synchronized into this GPU cache, random indices are moved to the device, and the sampled batch is gathered from the cached replay tensors. Thus, replay-cache maintenance and random replay access are part of the learner's hot update path.
#A.2 Sample-Before-Transfer Replay Pipeline
UniLab moves the replay boundary from the replay buffer to the sampled batch. The collector still performs CPU actor inference, environment stepping, and replay insertion. Once the learner requests the next training batch, the collector samples rows from a replay snapshot on the CPU and packs them into one of two shared pack slots. On CUDA, these pack slots are registered as pinned host-memory sources for asynchronous H2D transfer. A learner-side background H2D submit thread then transfers the packed batch into the cold GPU batch slot while the learner consumes the current hot slot.

#A.3 Trace-Based Attribution
We analyze A100 Perfetto traces for the baseline GPU-cache SAC path and the UniLab double-buffer path. These traces provide mechanism and timing evidence: they show where replay sampling, H2D transfer, learner updates, and weight publication occur.
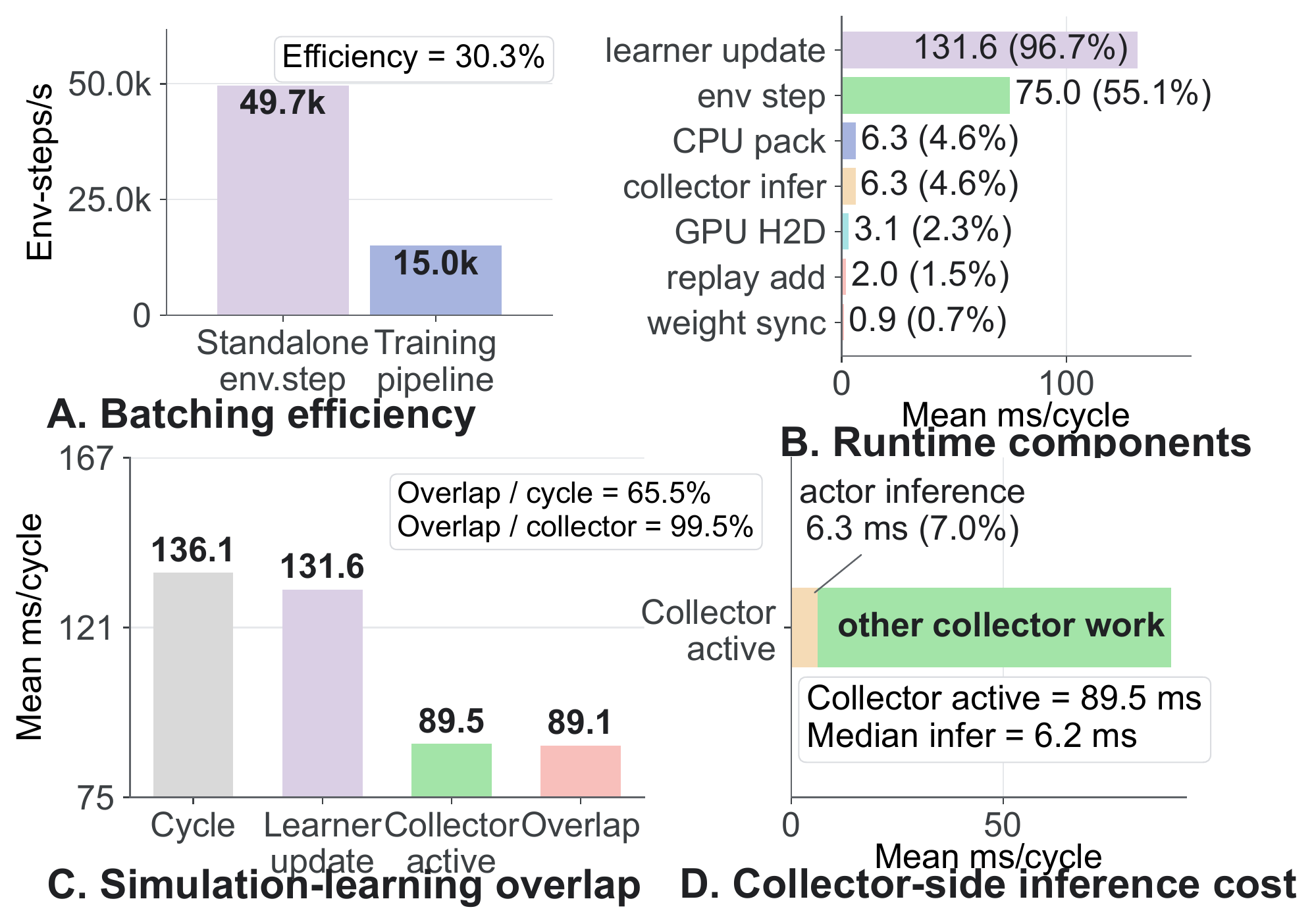
In the traced 500-iteration window, the double-buffer path reduces training time from 107.50 s to 70.58 s, a 34.34% reduction in wall-clock time. After dropping the first five cycles, the mean learner cycle decreases from 211.31 ms to 136.10 ms. With 2048 environment steps per learner cycle, this corresponds to an increase from 9.69k to 15.05k environment steps per second.
The clearest change is on the replay hot path. In the baseline trace, learner/replay_sample takes 3.64 ms on average and includes lazy replay synchronization. In the UniLab trace, learner-side replay consumption is reduced to 0.23 ms on average. Replay preparation still exists, but it is moved out of the learner hot path: CPU packing takes 6.30 ms, and GPU H2D transfer takes 3.13 ms, while 99.50% of collector-active time overlaps with learner updates.
#A.4 Ablating the Path from GPU-Cache SAC to Sample-Before-Transfer
We run a SAC replay-path ablation on the same A100 machine. The four variants preserve SAC's objective and update equations; only the replay boundary changes. The variants form a controlled migration chain: C (GPU-cache compatibility control) → B (modern framework, GPU-cache) → A (sampled-batch transfer, synchronous) → Baseline (pinned double-buffer).
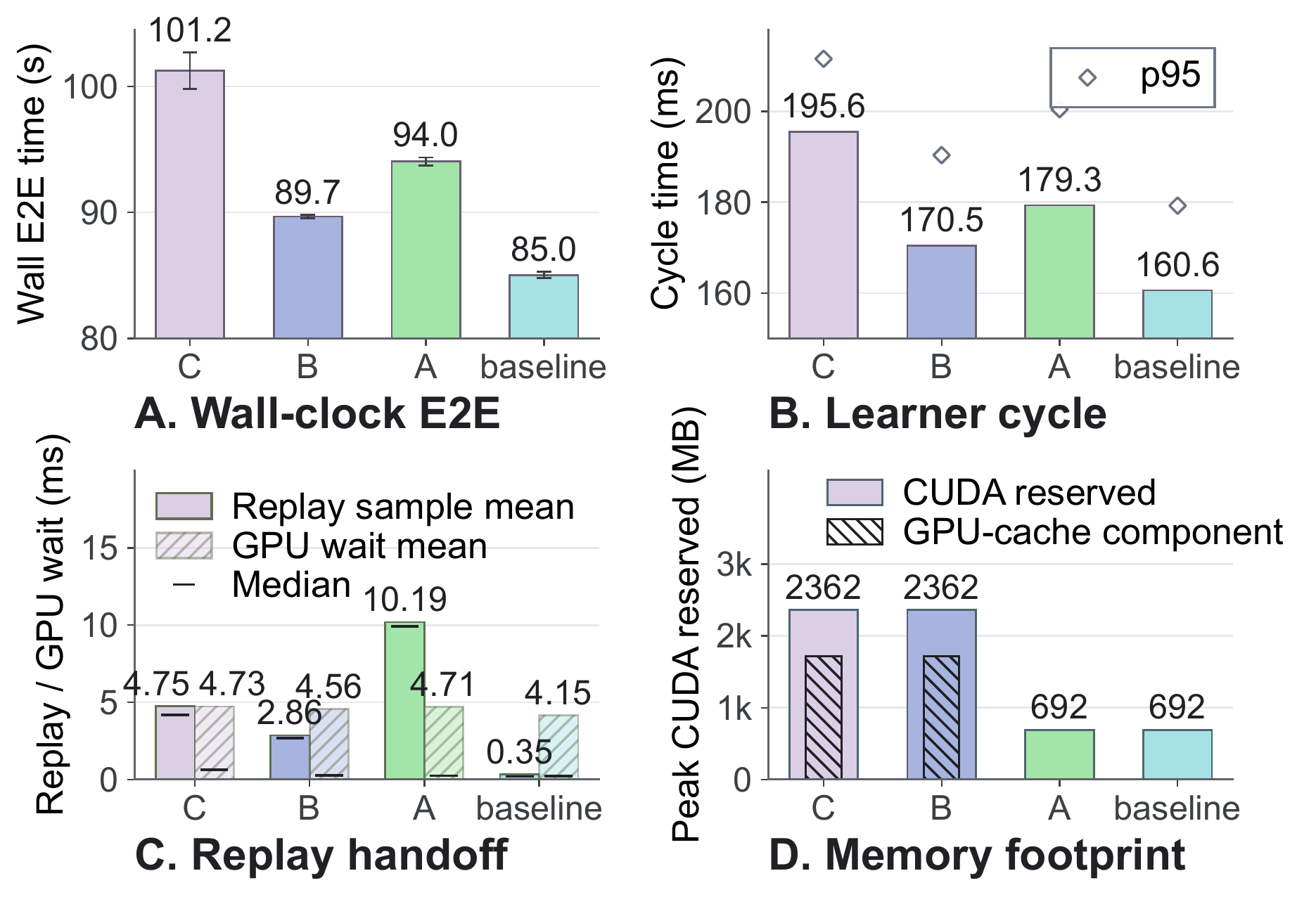
Moving from B to A removes the GPU-cache component and reduces peak CUDA reserved memory from 2362 MB to 692 MB. Moving from A to the baseline keeps the low-memory CPU-resident replay design and changes the transfer mechanism: pinned shared pack slots, one-tick asynchronous H2D, and hot/cold GPU slots reduce learner-side replay consumption from 10.19 ms to 0.35 ms. Relative to C, the final baseline reduces wall time from 101.23 s to 85.04 s while also removing the GPU-cache footprint.
#A.5 Buffer and Communication Overhead
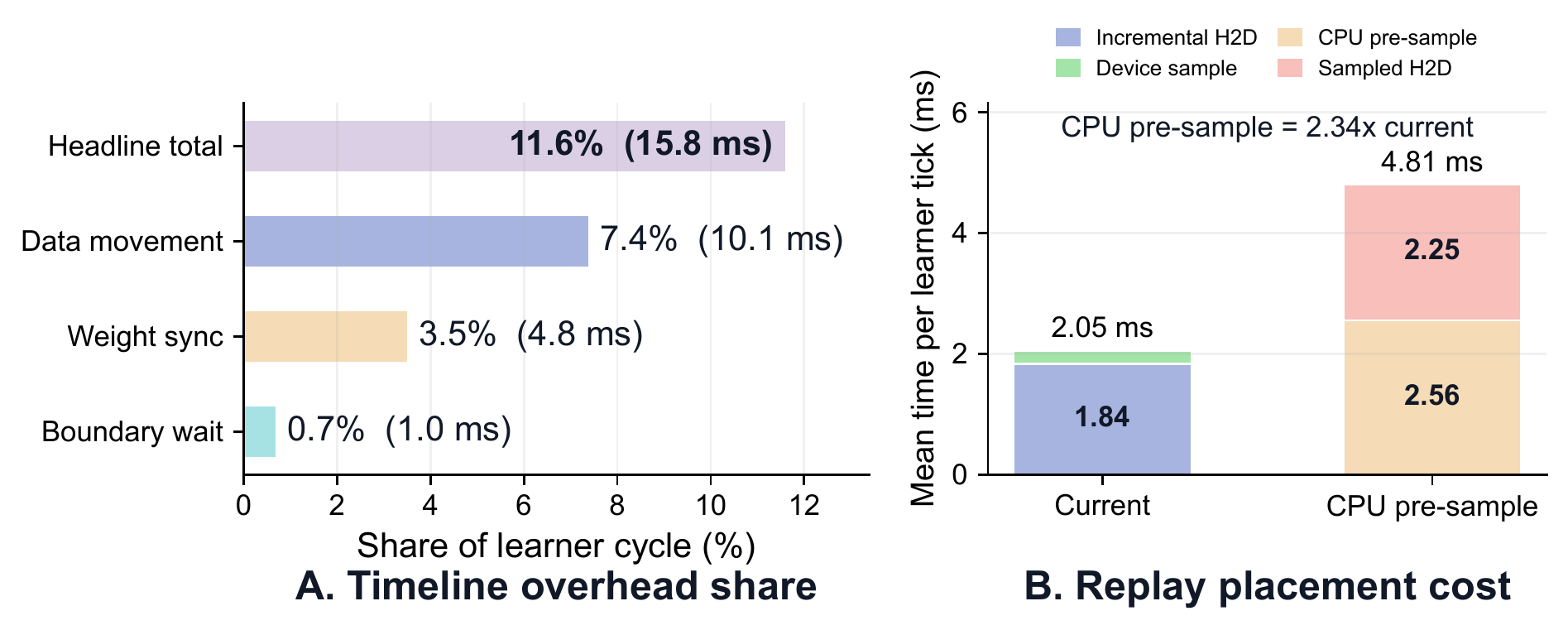
In the optimized trace, the counted data-movement, synchronization, and boundary-wait overhead total is 15.82 ms per cycle, or 11.62% of the 136.10 ms mean learner cycle. Data movement is the largest counted component at 10.07 ms per cycle, weight synchronization contributes 4.79 ms, and residual boundary waiting contributes 0.96 ms.
#Appendix B. Domain Randomization Backends and Lifecycle
Domain randomization in UniLab is implemented as a task/backend contract rather than as an algorithm-level feature. A task-owned DomainRandomizationProvider samples the quantities that are meaningful for the workload, while the simulator backend advertises which physical overrides it can apply. The runtime mediator, DomainRandomizationManager, validates this contract, applies cold-start model variants before backend materialization, injects reset payloads into sparse environment resets, and schedules interval perturbations before physics stepping.
#B.1 Runtime Lifecycle
The important systems detail is that reset-time randomization is sparse: only the environments listed in env_ids receive a new state and a new randomization payload. Interval randomization is different: it is checked once per vectorized environment step, before the backend advances physics.
| Lifecycle | Trigger | Owner | Randomized State |
|---|---|---|---|
| Backend initialization | DR init hook before backend materialize() | Task provider builds init plan; backend materializes variants | Persistent model or geometry variants (e.g., object-scale via GeomSizeOverride) |
| Sparse reset | Environment creation and later reset of terminated env_ids | Task provider samples reset state; backend applies supported fields | Pose, velocity, commands, mass, COM, gravity, friction, actuator gains |
| Scheduled interval | Each vectorized step | Task provider builds interval plan; backend stages perturbation | Push forces and body-force perturbations |
| Observation construction | Every task observation update | Task code | Actor observation noise, history/bias terms |
| Evaluation and playback | Same environment contract as training | Training/evaluation entrypoint | Shared contract; deterministic runs disable relevant switches |
#B.2 Backend Implementation
MuJoCoUni. MuJoCoUni implements reset-time randomization through BatchEnvPool.reset(env_ids, initial_state, randomization=None) which receives both the new physics state and an optional dictionary of model-field patches. Each payload has leading dimension len(env_ids), so reset cost scales with the number of environments that actually terminate. Fields that affect MuJoCo derived constants are patched before the reset/forward path and refreshed with mj_setConst.
MotrixSim. MotrixSim implements the same task/backend contract with MotrixSim-native override APIs. During set_state, the backend resets the selected data slice, clears staged body forces, applies init-time geometry-size overrides, applies supported reset randomization, writes the new DOF state, and runs forward kinematics. Friction, gravity, and actuator-gain randomization are conditional capabilities: they are enabled only when the loaded MotrixSim model exposes the corresponding override methods.
#B.3 Supported Randomization Families
| Family | Lifecycle | MuJoCoUni | MotrixSim |
|---|---|---|---|
| Model/geometry variants | Init | Precompiled MjModel variants with per-env assignments | Per-env geometry-size overrides |
| Initial state & task conditions | Reset | Backend receives sampled qpos/qvel | Same contract after DOF layout conversion |
| Base/body mass | Reset | base_mass_delta and full body_mass | Base-link mass delta and full link-mass override |
| Gravity | Reset | gravity payload | Conditional gravity override |
| Contact friction | Reset | Full geom_friction payload | Conditional collision-geom friction overrides |
| Actuator gains | Reset | kp and kd payloads | Conditional per-actuator Kp/damping overrides |
| External perturbations | Interval | Push and body-force via xfrc_applied | Push forces through link external force |
| Observation noise | Obs step | Task-side NumPy noise | Same task-side path |
#B.4 Implications for Cross-Backend Experiments
The shared contract lets a task express randomization once, but the effective randomization set is still backend-dependent. A randomization item should be interpreted as active only when the task configuration enables it and the selected backend advertises support for the corresponding field. MuJoCoUni exposes a wider reset-field surface for inertial fields, whereas MotrixSim can match many common locomotion and manipulation settings through link, geom, gravity, actuator, and external-force override APIs when the loaded model supports them.
#Appendix C. Task and Algorithm Details
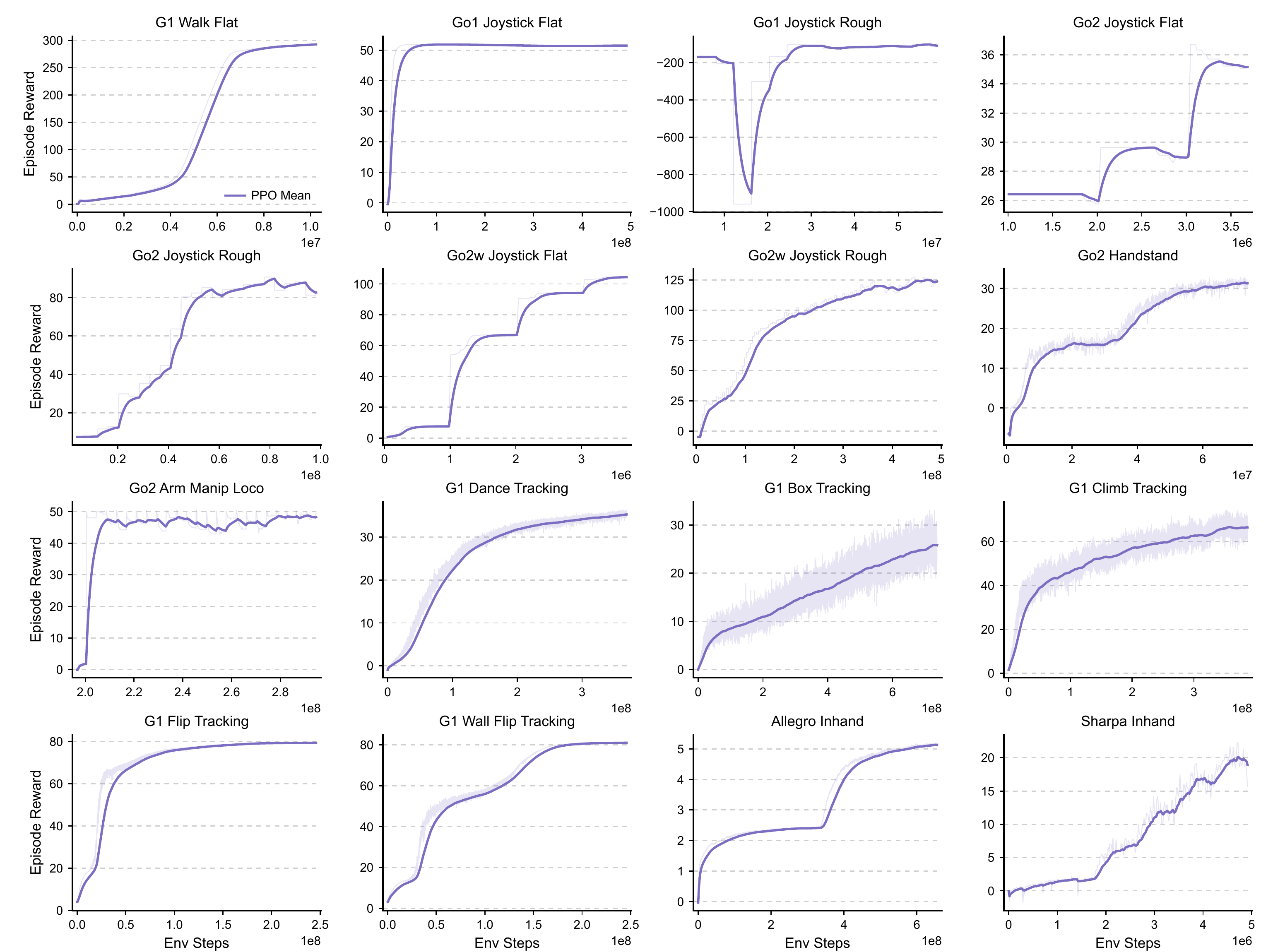
Detailed per-task specifications (observation space, action space, reward weights, domain randomization) and per-algorithm hyperparameter tables are provided in the full paper PDF. This appendix covers locomotion, motion tracking, manipulation-locomotion, and dexterous-hand task families, as well as PPO, APPO, and SAC algorithm configurations.
#Citation
@article{jia2026unilab,
title = {UniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms},
author = {Yufei Jia and Zhanxiang Cao and Mingrui Yu and Heng Zhang and Shenyu Chen and Dixuan Jiang and Meng Li and Xiaofan Li and Yiyang Liu and Junzhe Wu and Zheng Li and XiLin Fang and Ting-Yu Tsui and Shengcheng Fu and Haoyang Li and Anqi Wang and Zifan Wang and Dongjie Zhu and Chenyu Cao and Zhenbiao Huang and Ziang Zheng and Jie Lu and Xin Ma and Zhengyang Wei and Xiang Zhao and Tianyue Zhan and Ye He and Yuxiang Chen and Yizhou Jiang and Yue Li and Haizhou Ge and Yuhang Dong and Fan Jia and Ziheng Zhang and Meng Zhang and Xiwa Deng and Zhixing Chen and Hanyang Shao and Chenxin Dong and Yixuan Li and Yizhi Chen and Bokui Chen and Kaifeng Zhang and Hanqing Cui and Yusen Qin and Ruqi Huang and Lei Han and Tiancai Wang and Xiang Li and Yue Gao and Guyue Zhou},
journal = {arXiv preprint arXiv:2605.30313},
year = {2026},
url = {https://arxiv.org/abs/2605.30313}
}