Go1 — Joystick (flat)
Embodied Reinforcement Learning具身强化学习
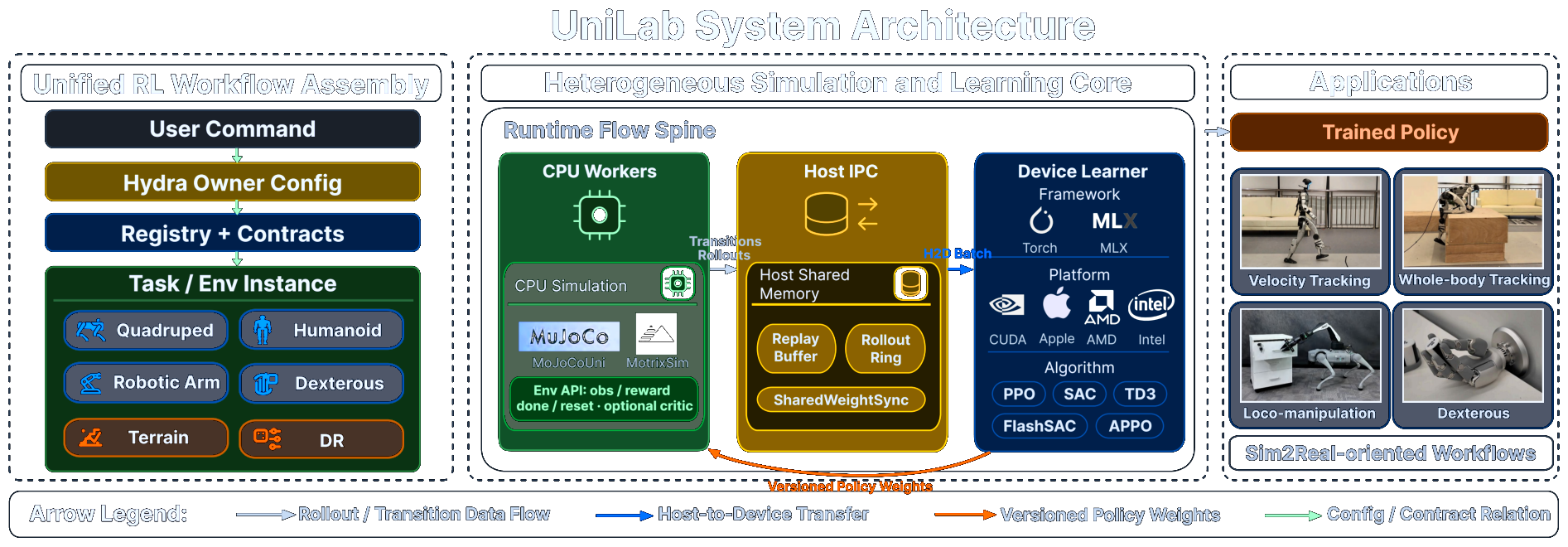
UniLab decouples CPU simulation, GPU learning, and a shared-memory runtime so that simulators and learners stop waiting on each other. The result is an end-to-end pipeline that runs unchanged on Apple Silicon (MPS / MLX) — a first-class target where prior training stacks force a Linux/CUDA detour — plus NVIDIA, AMD, and Intel, and reaches policy targets 3–10× faster than tightly-coupled GPU-centric baselines. UniLab 将 CPU 仿真、GPU 学习 与共享内存运行时解耦,让仿真器与学习器不再相互等待。最终得到一条端到端流水线,可在 Apple Silicon(MPS / MLX) 上原样运行——以往的训练栈在此被迫绕道 Linux/CUDA——并支持 NVIDIA、AMD 与 Intel,以 3–10× 的速度达到策略目标,优于紧耦合的 GPU 中心化基线。
Contributions贡献
01
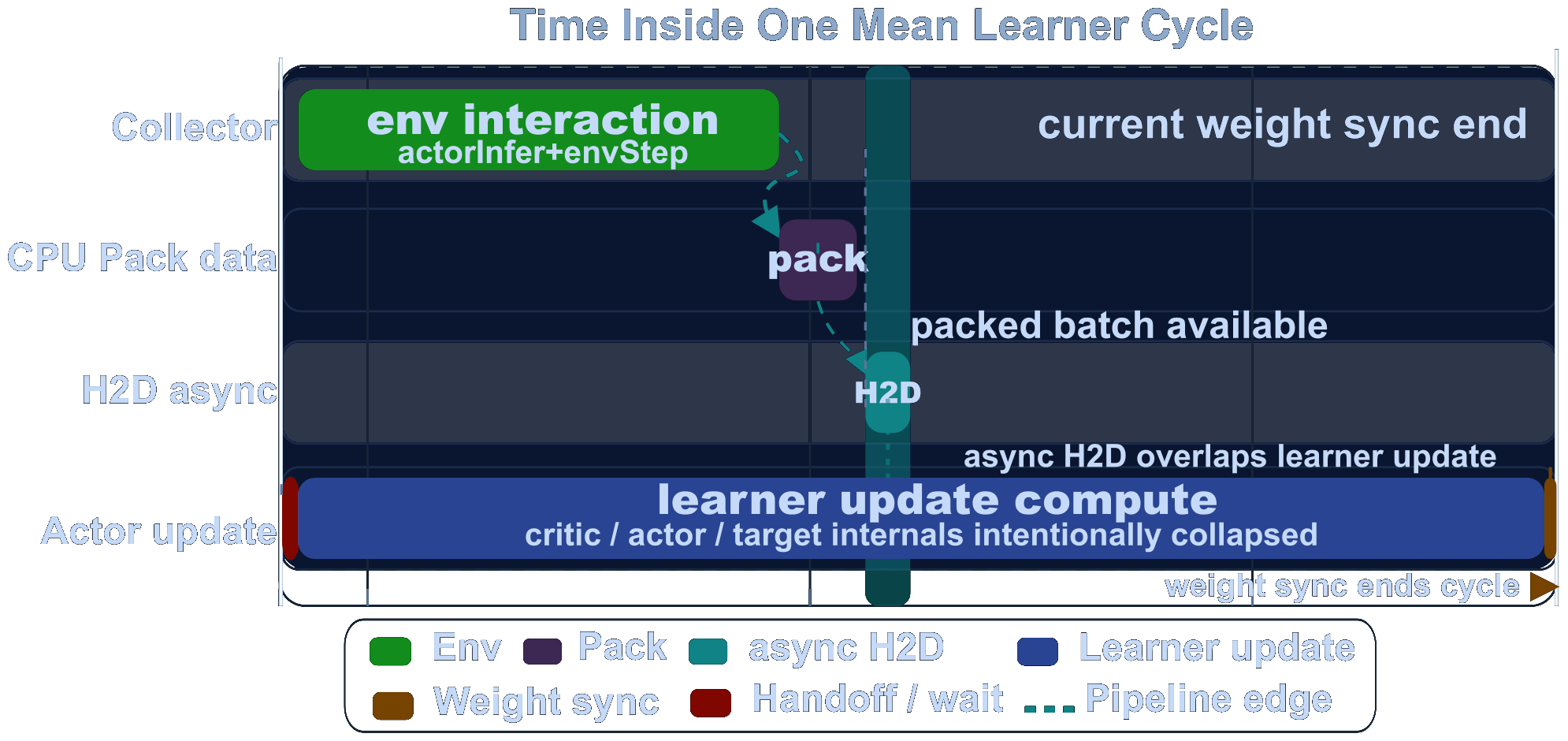
Independent CPU rollout workers stream transitions through a lock-free shared-memory buffer to a GPU learner. Asynchronous weight sync removes the simulator–learner stall that dominates tightly-coupled pipelines. 独立的 CPU rollout 工作进程通过无锁共享内存缓冲区,将 transition 流式传给 GPU 学习器。异步权重同步消除了紧耦合流水线中主导性的仿真器–学习器阻塞。
02
Train end-to-end on Apple Silicon (MPS / MLX) — no Linux box required — with the same stack also running on NVIDIA (CUDA), AMD (ROCm), and Intel (Arc / XPU). Match your hardware, not the framework's assumptions. 在 Apple Silicon(MPS / MLX) 上端到端训练——无需 Linux 机器——同一套栈同样运行在 NVIDIA(CUDA)、AMD(ROCm)与 Intel(Arc / XPU)上。匹配你的硬件,而不是框架的假设。
03
On-policy (PPO, APPO, HIM-PPO), off-policy (SAC, TD3, FlashSAC), and distillation (HORA) all ride the same heterogeneous runtime — including async PPO adapted for decoupled execution. On-policy(PPO、APPO、HIM-PPO)、off-policy(SAC、TD3、FlashSAC)与蒸馏(HORA)都运行在同一套异构运行时上——包括为解耦执行改造的异步 PPO。
Architecture架构
UniLab is built around two ideas: spatial decoupling of simulation and learning across heterogeneous devices, and temporal overlap of trajectory collection, gradient steps, and weight sync. UniLab 围绕两个理念构建:在异构设备间对仿真与学习进行空间解耦,以及对轨迹采集、梯度更新与权重同步进行时间重叠。
PPO and APPO use trajectory-oriented runners. Each algorithm declares its sync requirement and buffer usage; the runtime schedules accordingly. PPO 与 APPO 使用面向轨迹的 runner。每个算法声明自己的同步需求与缓冲区用法,运行时据此调度。
A single shared buffer holds rollouts and replay slices; weight sync is a lock-free publication channel. No serialization, no per-step round-trip — workers and learner only meet through memory. 单个共享缓冲区保存 rollout 与 replay 切片;权重同步是一条无锁发布通道。无序列化、无逐步往返——工作进程与学习器只通过内存相遇。
Coverage覆盖
 Apple Silicon (MPS / MLX)
Apple Silicon (MPS / MLX)
 NVIDIA CUDA
NVIDIA CUDA
 AMD ROCm
AMD ROCm
 Intel Arc / XPU
Intel Arc / XPU
Comparison对比
UniLab is not another GPU-resident simulator. It is a heterogeneous runtime that lets the simulator and the learner each run on the hardware they are best at. UniLab 并非又一个 GPU 驻留仿真器,而是一套异构运行时——让仿真器与学习器各自运行在最擅长的硬件上。
| Framework框架 | GPU-resident simGPU 仿真器 | Heterogeneous runtime异构运行 | PPO / SAC / TD3PPO / SAC / TD3 | Hardware / backend support硬件 / 平台支持 |
|---|---|---|---|---|
| IsaacLab | ● | ○ | ◐ |
|
| IsaacGym | ● | ○ | ◐ |
|
| mjlab | ● | ○ | ◐ |
|
| Genesis | ● | ○ | ◐ |
|
| IsaacSim | ● | ○ | ◐ |
|
| UniLab | ○ | ● | ● |
|
● supported ◐ partial ○ not supported. Platform icons denote supported hardware/backend targets; the amber outline indicates evaluation-only or limited support. ● 支持 ◐ 部分支持 ○ 不支持。平台图标表示支持的硬件/后端目标;琥珀色轮廓表示仅限评估或有限支持。
Results结果

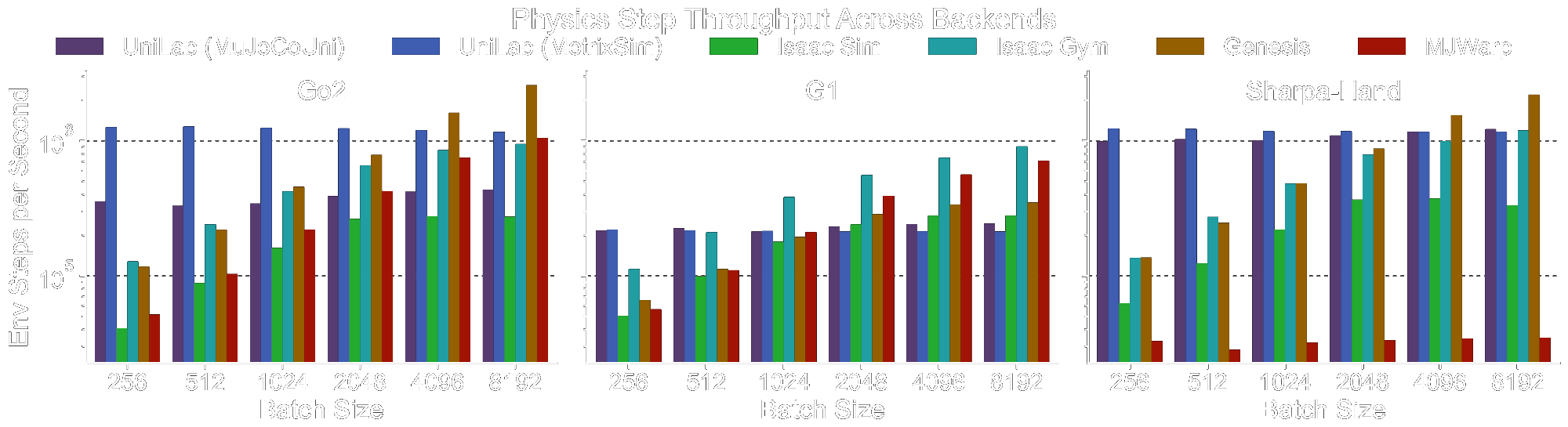
From sim to real从仿真到真机
The same heterogeneous training stack produces policies that transfer to hardware. Below, a short video walks through UniLab's to-real experiments across six real-robot tasks — and right after it, you can drive the trained policies yourself in the browser. 同一套异构训练栈产出的策略可迁移到真实硬件。下面这段短视频展示了 UniLab 在六个真实机器人任务上的真机实验——紧接其后,你可以在浏览器中亲自驱动训练好的策略。
Task Gallery任务画廊
Each card opens a MotrixSim demo for a UniLab-trained policy, with compact notes on training time and behavior. 每张卡片都会打开一个 MotrixSim 演示,展示 UniLab 训练的策略。

Cross-Platform跨平台
Almost every robot-RL stack today ships Linux/CUDA-first; Apple Silicon is an after-thought, if it works at all. UniLab is the opposite: macOS is a first-class target, running the same code on MPS and MLX as it does on CUDA, ROCm, and Intel XPU. 如今几乎所有机器人 RL 栈都以 Linux/CUDA 为先;Apple Silicon 即便能用也只是事后补充。UniLab 恰恰相反:macOS 是一等公民,在 MPS 与 MLX 上运行的代码,与在 CUDA、ROCm、Intel XPU 上完全相同。
| Platform | Hardware | Backend | Representative task | Trained |
|---|---|---|---|---|
|
macOS · MPS / MLX
|
M3 / M5 Max, MacBookNeo | MotrixSim / MuJoCo | Go2 joystick (PPO), G1 walk-flat (FastSAC) | ● |
|
Linux · CUDA
|
RTX 4090 + R9-9950X3D | MotrixSim / MuJoCo | G1 walk-flat, Go2 joystick, Allegro in-hand | ● |
|
Linux · ROCm
|
AMD GPU | MotrixSim / MuJoCo | G1 walk-flat (ROCm AMP) | ● |
|
Linux · XPU
|
Intel Arc | MotrixSim / MuJoCo | Go2 joystick | ● |
See the paper appendix for full per-platform setup, seeds, and wall-clock numbers.
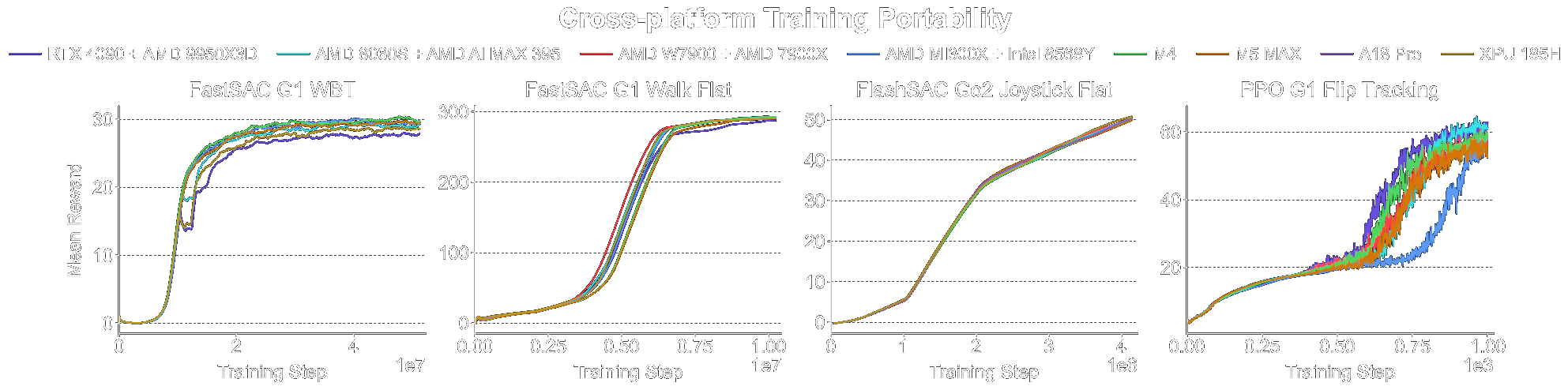
| Task任务 | RTX 4090 (baseline) |
RTX 4090 + AMD 9950X3D |
AMD 8060S + AMD AI MAX 395 |
AMD W7900 + AMD 7900X |
AMD MI300X + Intel 8568Y |
M5 MAX | M4 | A18 Pro | XPU 185H |
|---|---|---|---|---|---|---|---|---|---|
| FastSAC G1 WBT | 58.8 | 18.5 | 33.6 | — | 29.3 | 75.0 | 280.7 | — | 446.1 |
| FastSAC G1 Walk Flat | 18.3 | 3.0 | 9.4 | 4.7 | 6.9 | 18.8 | 62.4 | — | 115.4 |
| FlashSAC Go2 Joystick Flat | 6.0 | 1.1 | 4.2 | 1.8 | 2.8 | 4.5 | 14.9 | 32.2 | 20.0 |
| PPO G1 Flip Tracking | 109.0 | 16.4 | 19.6 | 15.2 | 12.5 | 16.8 | 31.2 | — | — |
Wall-clock training time (minutes) per (task, platform) pair; — marks runs not measured. 各平台 wall-clock 训练时间(分钟),按(任务,平台)列出;— 表示未测量的组合。
Cite引用
@article{jia2026unilab,
title = {UniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms},
author = {Yufei Jia and Zhanxiang Cao and Mingrui Yu and Heng Zhang and Shenyu Chen and Dixuan Jiang and Meng Li and Xiaofan Li and Yiyang Liu and Junzhe Wu and Zheng Li and XiLin Fang and Ting-Yu Tsui and Shengcheng Fu and Haoyang Li and Anqi Wang and Zifan Wang and Dongjie Zhu and Chenyu Cao and Zhenbiao Huang and Ziang Zheng and Jie Lu and Xin Ma and Zhengyang Wei and Xiang Zhao and Tianyue Zhan and Ye He and Yuxiang Chen and Yizhou Jiang and Yue Li and Haizhou Ge and Yuhang Dong and Fan Jia and Ziheng Zhang and Meng Zhang and Xiwa Deng and Zhixing Chen and Hanyang Shao and Chenxin Dong and Yixuan Li and Yizhi Chen and Bokui Chen and Kaifeng Zhang and Hanqing Cui and Yusen Qin and Ruqi Huang and Lei Han and Tiancai Wang and Xiang Li and Yue Gao and Guyue Zhou},
journal = {arXiv preprint arXiv:2605.30313},
year = {2026},
url = {https://arxiv.org/abs/2605.30313}
}@article{jia2026mujocouni,
title={MuJoCoUni: Persistent Batched Runtime Primitives for MuJoCo},
author={Jia, Yufei and Wu, Junzhe},
journal={arXiv preprint arXiv:2605.24922},
year={2026}
}
@software{motrixsim2026,
title = {MotrixSim: A Physics Simulation Engine for Robotics and Embodied AI},
author = {{Motphys Team}},
year = {2026},
url = {https://motrixsim.readthedocs.io/},
note = {Python binary package}
}Acknowledgments致谢